A CUDA stream is a queue of GPU operations that are executed in a specific order.
The order in which the tasks are added to this queue determines their order of execution.
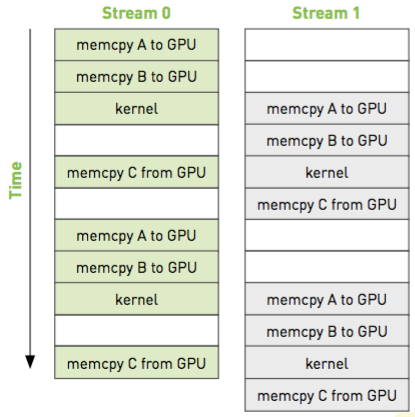
Independent streams of operations can be executed concurrently and asynchronously.
Streams take advantage of the capability of the GPU to overlap kernel execution with memory copy operations.
Nearly all CUDA enabled cards with a compute capability of 1.1 or higher can do this.
Single CUDA Streams
To test if a GPU is capable of the overlapped memory copies, we can run the following sample.
#include <stdio.h>
int main( void ) {
cudaDeviceProp prop;
int whichDevice;
cudaGetDevice( &whichDevice );
cudaGetDeviceProperties( &prop, whichDevice ) ;
if(!prop.deviceOverlap){
printf( "Device will not handle overlaps, so no speed up from streams\n" );
}else{
printf( "Device will handle overlaps\n" );
}
return 0;
}
Single CUDA Streams
The overlap capability will be relevant when we move to the use of multiple streams.
To set up a stream, we will make use of cudaStreamCreate
We can then begin to add items to the stream of operations.
Single CUDA Streams
To motivate this example, we will use a cuda kernel that calculates the average of three values supplied from two vectors -just a toy calculation.
__global__ void kernel(int *a, int *b, int *c) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
int idx1 = (idx + 1) % 256;
int idx2 = (idx + 2) % 256;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / 2;
}
}
Single CUDA Streams
The first step is to allocate some host memory to hold the a, b and c arrays.
In order to use the host memory locations within the stream (i.e. Copy their values to and from the GPU in the stream), it will need to be allocated as page-locked memory.
Page-locked memory is the same as normal heap memory (that we would allocate through malloc), except it is guaranteed never to be swapped into the virtual memory on disk by the OS.
The OS ensures that the memory is always within the physical memory of the system.
Single CUDA Streams
Because the memory is never moved by the OS, the GPU can use direct memory access to copy data from this location in the host.
DMA works without intervention from the CPU.
Interestingly, even when copying from pageable memory, the GPU still uses DMA.
The pageable memory block (potentially residing in the virtual memory on disk) is copied to a page-locked section of memory for staging.
The DMA transfer is then done from the staging location to the GPU.
Ergo, transfers from pageable memory are bounded by the transfer speed of the virtual memory.
Single CUDA Streams
Remember that your system has a finite amount of physical memory - so be careful with the page-locked memory allocation.
The system will run our of memory much faster if page-locked memory is overused.
Know the limits of you system and the other applications that share the memory.
Single CUDA Streams
To allocate paged-locked memory, we can use the cudaHostAlloc() function.
cudaError_t cudaHostAlloc(void ** pHost,
size_t size,
unsigned int flag)
Allocates size bytes of host memory that is page-locked and accessible to the device.
Parameters:
pHost - Device pointer to allocated memory
size - Requested allocation size in bytes
flags - Requested properties of allocated memory. We will use cudaHostAllocDefault
Single CUDA Streams
We will allocate some page-locked memory for our asynchronous stream.
We will fill the a and b arrays with random values.
// allocate page-locked memory, used to stream
cudaHostAlloc( (void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault );
cudaHostAlloc( (void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault );
cudaHostAlloc( (void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault );
for (int i = 0; i < FULL_DATA_SIZE; i++) {
host_a[i] = rand();
host_b[i] = rand();
}
Single CUDA Streams
We will now copy our page-locked memory blocks to the GPU.
Up until now, we have used the cudaMemcpy
This is a synchronous function that only returns when the copy is completed.
We will use cudaMemcpyAsync which returns to the caller immediately. The copy operation is completed at some time after this call.
A cudaStream_t is passed in as a parameter and allows the program to guarantee that the copy will be completed before the next operation in the stream takes place.