An atomic function performs a read-modify-write atomic operation on one 32-bit or
64-bit word residing in global or shared memory.
The operation is atomic in the sense that it is guaranteed to be performed without interference from other threads.
Mutual exclusion is enforced, removing the possibility of Lost Updates occurring as a result of race conditions.
CUDA provides a full suite of atomic functions for performing arithmetic operations.
Atomic Operations and Mutual Exclusion
The first function we will look at is atomicAdd( ... )
int atomicAdd(int* address,
int val
);
unsigned int atomicAdd(unsigned int* address,
unsigned int val
);
unsigned long long int atomicAdd(unsigned long long int* address,
unsigned long long int val
);
float atomicAdd(float* address,
float val
);
Atomic Operations and Mutual Exclusion
Reads the 32-bit or 64-bit word old located at the address address in global or shared
memory, computes (old + val), and stores the result back to memory at the same
address.
These three operations are performed in one atomic transaction.
The function returns old.
Atomic Operations and Mutual Exclusion
To motivate our discussion we will look at an example that involves calculating a total from a vector.
Here we have an example of a CUDA kernel with a thread race (updates will be lost in the result addition):
There are atomic functions for a range of aggegations
atomicSub - subraction
atomicMin - Min
atomicMax - Max
There are a couple of more specialised ones:
int atomicExch(int* address, int val);
unsigned int atomicExch(unsigned int* address, unsigned int val);
unsigned long long int atomicExch(unsigned long long int* address, unsigned long long int val);
float atomicExch(float* address, float val);
Reads the 32-bit or 64-bit word old located at the address address in global or shared
memory and stores val back to memory at the same address.
Atomic Operations and Mutual Exclusion
int atomicCAS(int* address, int compare, int val);
unsigned int atomicCAS(unsigned int* address, unsigned int compare, unsigned int val);
unsigned long long int atomicCAS(unsigned long long int* address, unsigned long long int compare, unsigned long long int val);
Reads the 32-bit or 64-bit word old located at the address address in global or shared
memory, computes (old == compare ? val : old), and stores the result back
to memory at the same address.
These three operations are performed in one atomic
transaction.
The function returns old (Compare And Swap).
Atomic Operations and Mutual Exclusion
Recall from from module 2, that atomic operations don't stop the problem of synchronisation.
There are situation where a sequence of actions must be carried out in within atomic transactions.
CUDA does not provide functions for mutexes.
We can implement them ourselves using the atomic functions.
However there is an issue - this does not work on all GPUs.
Spin locks can cause a deadlock due to the thread scheduling.
An example of mutex locks in action can be found in the dotProduct.cu - this frequently locks up on bourbaki.
Mutexes and critical sections should be used sparingly as they circumvent many of the benefits of the data-parallel approach for computation.
Warps and Divergence
As we discussed in previous lectures, CUDA threads are executed by the block.
In order for a block to be executed, it is assigned to one of the GPUs streaming multiprocessors (SM).
The GPU on bourbaki has 108 such cores with 64 threads per core. (see the deviceQuery example)
Once a block of threads has been allocated to a processor, it is them further divided into 32-thread units called warps
The number of threads per warp (32) is implementation specific and may change in the future - know the properties of the GPU that you are targeting.
Warps and Divergence
The warps are structured so that they consist of consecutive threadIdx values.
threads 0 ... 31 will be in the first warp, threads 32 ... 63 will be in the next.
The number of warps in a block will be determined by dividing the number of threads in the block by 32.
The warps are the unit used by the GPU for thread scheduling.
Warps and Divergence
The processors can switch between warps with no apparent overhead.
Just like POSIX threads, CUDA threads can be in different states - Waiting for Data, Ready to Execute or Executing
Waiting for data occurs when threads within a warp need the result from another calculation.
Once the data is available, the are ready to execute and the whole warp will be scheduled onto the processor.
The ability to schedule warps within a block, gives the GPU the ability to tolerate long-latency operations.
Warps and Divergence
Threads are always allocated in warp-sized denominations, even if the logic in the program does not make use of them.
When we are working with the kernel launch configuration, we should maximise the number of warps that a SM has to work with.
This will give the scheduler the flexibility to ensure that the there is no idle time.
kernel<<<N, 1>>> ( ... ) /* Bad Design - the warp will be almost empty*/
kernel<<<N / 32, 32>>>( ... ) /* Okay Design - the warp will be full*/
kernel<<<N / 128, 128>>>( ... ) /* Better Design - Maximise the number of full warps */
Warps and Divergence
When the number of threads is not a multiple of the block size, use some bounds checking:
__global__ void kn(int n, .... )
{
int i = threadIdx.x + blockDim.x * blockIdx.x;
if (i < n)
{
// Your task
}
}
This prevents buffer over-runs if we intend to use threadIdx.x to calculate an array index.
This is the pattern that many of the examples we have looked at this far have used.
Warps and Divergence
Lets motivate our next section with a code snippet:
__shared__ float partialSum[]
...
unsigned int t = threadIdx.x;
for (unsigned int stride = 1; stride < blockDim.x; stride *= 2){
__syncthreads();
if (t % (2*stride) == 0)
partialSum[t] += partialSum[t+stride];
}
Warps and Divergence
The code snippet conducts a parallel sum reduction.
The original array is copied from global memory to shared memory - the result is then copied back (these are not shown).
Each iteration of the loop completes one round of the reduction.
the __syncthreads(); call ensures that all threads will use results from the previous iteration.
Warps and Divergence
Very similar in structure to the tree communication structure we looked at when we covered MPI.
Warps and Divergence
The approach requires log2(N) rounds, giving an efficiency of O(N) - so reasonably efficient
There is divergence caused by the branching.
Divergence causes some of the threads within each warp to block - essentially the branches need to be serialised
The first pass with run all threads that step into the if statement.
A second pass will be required to run those that do not enter the if statement.
This decreases the efficiency of the approach.
Warps and Divergence
The aim is to get all threads within a warp taking the same path.
We can still have divergence, it just needs to be organised in a different way.
In our example, we can modify the stride to limit the divergence within each warp.
Warps and Divergence
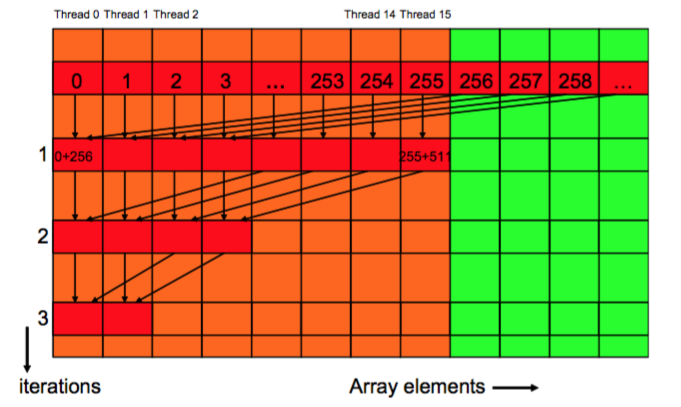
Instead of adding neighbour elements in the first round, it adds elements that are half a section away from each other.
__shared__ float partialSum[]
unsigned int t = threadIdx.x;
for (unsigned int stride = blockDim.x; stride > 1; stride /= 2){
__syncthreads();
if (t < stride)
partialSum[t] += partialSum[t+stride];
}
Warps and Divergence
Measuring Performance
Performing performance measures with CUDA involves the use of cudaEvent_t structs, the cudaEventCreate function and the cudaEventRecord function.
The general pattern (without error checking) looks like:
cudaEvent_t start;
cudaEventCreate(&start);
cudaEvent_t stop;
cudaEventCreate(&stop);
// Record the start event
cudaEventRecord(start, NULL);
...
//Launch kernels etc.
...
// Record the stop event
cudaEventRecord(stop, NULL);
// Wait for the stop event to complete
cudaEventSynchronize(stop);
float msecTotal = 0.0f;
cudaEventElapsedTime(&msecTotal, start, stop);