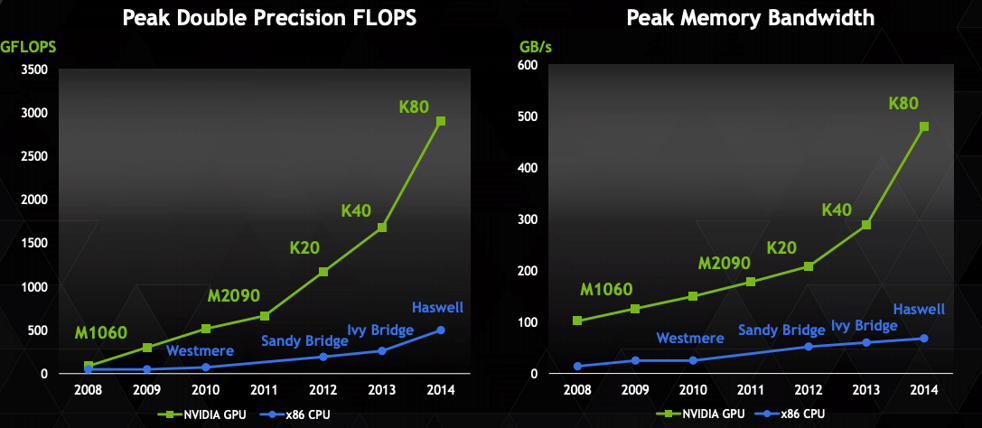
"Driven by the insatiable market demand for realtime, high-definition 3D graphics, the programmable Graphic Processor Unit or GPU has evolved into a highly parallel, multithreaded, manycore processor with tremendous computational horsepower and very high memory bandwidth " - CUDA C programming guide.
As a result, general purpose programming platforms have been developed so that the computational power of the GPU can be harnessed for non-graphics related computation.
GPUs are well suited to problems that can be expressed as data-parallel computing (i.e. Single Instruction, Multiple Data - SIMD)
NVidia's flavour of this technology is the Compute Unified Device Architecture (CUDA)
Welcome to GPU Programming with NVidia CUDA
Welcome to GPU Programming with NVidia CUDA
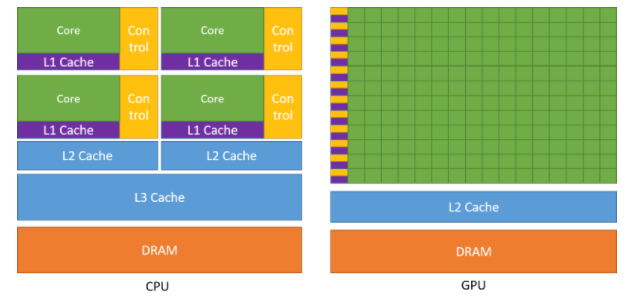
Within the GPU itself, a higher percentage of transistors are devoted to processing (e.g. ALUs).
A smaller percentage of the transistors are left for Cache memory and flow control.
GPUs are not optimised for processing branch-logic like their CPU cousins.
The result is a highly specialised processing unit that is well suited to applications that require the same instructions to be executed across a data set.
Welcome to GPU Programming with NVidia CUDA
The relative usage of the available transistors.
Welcome to GPU Programming with NVidia CUDA
We will be constructing software that runs on the GPU using the CUDA C programming interface.
CUDA C is based on the C programming language, with addition of some syntactical sugar for conveniently managing the GPU functions.
The programs are compiled through the NVidia C Compiler - nvcc.
nvcc is similar to the mpicc as it is essentially a wrapper for the gcc compiler with the additional language features built in.
Welcome to GPU Programming with NVidia CUDA
We will work with CUDA programs using the nvcc compiler directly with makefiles.
We will be working with CUDA code using Visual Studio Code with the CUDA Plugin installed.
The CUDA plugin includes required custom syntax highlighting and a simple debugger for CUDA.
Welcome to GPU Programming with NVidia CUDA
If you are working on your own system you can try Nsight.
The Nsight IDE is based upon the Eclipse IDE and shares many of its features.
nsight is NVidia's CUDA IDE that combine editor functionality with a system for managing run and build configurations.
Nsight also includes a comprehensive debugger that will allow you to see the contents of every memory location within every thread - this is the main reason for using the IDE.
It is quite buggy - so we will stick with VS Code to start with.
The CUDA Programming Model
CUDA Threads execute on a physically separate device from the Host machine.
This device has its own separate memory space and does not share (i.e. have access to) the host machine's memory.
This means that any data that is required by a CUDA function must be transferred on the GPU.
Any results from the CUDA functions must be transferred back to the host.
The CUDA Programming Model
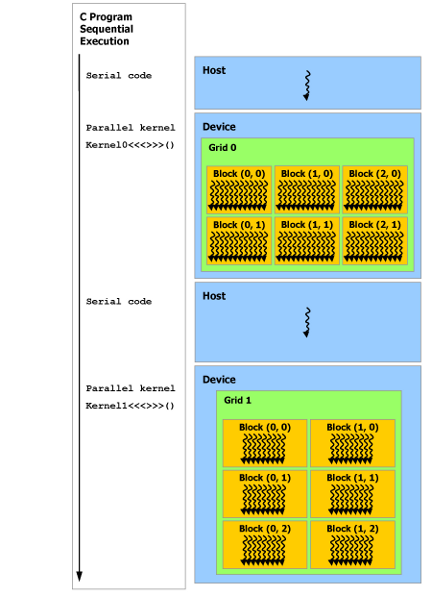
A typical CUDA program consists of serial elements that execute on the host machine (just like a normal program) and kernel functions that execute on the GPU.
When a kernel is executed, we specify how many instances of this kernel are executed on the GPU - i.e. the number of CUDA threads.
This means that when a kernel is invoked, identical logic is executed across the number of threads specified.
The CUDA Programming Model
The CUDA Programming Model
CUDA Kernels are executed N times in parallel by N different CUDA threads, as opposed to only once like regular C functions.
Before we start moving into coding up some functions, we will look at the thread hierarchy in CUDA.
CUDA Threads are analogous to the POSIX threads that we covered on module 2 for this course.
The key difference is there typically many more CUDA threads invoked when we make a kernel call - usually thousands.
The CUDA Programming Model
In order to effectively manage the large number of threads, they are organised into blocks
The blocks of threads can be one-dimensional, two dimensional or three dimensional.
Threads within a block will reside on the same processing core within the GPU.
As such, a single block can contain up to 1024 threads.
The CUDA Programming Model
Blocks are organised into a one-dimensional, two-dimensional, or three-dimensional grids of thread blocks.
The number of thread blocks in a grid is dictated by the number of processors on the system.
On the A100 on bourbaki:
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
This is from the deviceQuery example.
The CUDA Programming Model
Like POSIX threads, CUDA threads have shared memory:
Each thread has private local memory.
Each thread block has shared memory visible to all threads of the block and with the same lifetime as the block.
All threads have access to the same global memory.
The global, constant, and texture memory spaces are persistent across kernel launches by the same application.
The CUDA Programming Model
We can identify the individual threads using the threadIdx vector.
threadIdx is a three dimensional vector that contains the x, y and z coordinates for the thread.
for a two-dimensional block of size (Dx, Dy), the thread ID of a thread of index (x, y) is (x + y Dx)
for a three-dimensional block of size (Dx, Dy, Dz), the thread ID of a thread of index (x, y, z) is (x + y Dx + z Dx Dy).
The CUDA Programming Model
Now we will look at our first snippet of CUDA C.
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
The CUDA Programming Model
Kernel function definition is very similar to a normal C function, except for the __global__ qualifier.
Qualifiers are used to specify if a function executes on the host or the device:
The __global__qualifier declares a function as being a kernel. Such a function is:
Executed on the device,
Callable from the host,
Callable from the device for devices of compute capability 3.x
The CUDA Programming Model
The __device__ qualifier declares a function that is:
Executed on the device,
Callable from the device only.
Used to create a reusable function that is callable from a kernel function.
The __host__ qualifier declares a function that is:
Executed on the host,
Callable from the host only.
The CUDA Programming Model
The __global__ and __host__ qualifiers cannot be used together.
The __device__ and __host__ qualifiers can be used together however, in which case the function is compiled for both the host and the device.
The CUDA Programming Model
The kernel call has some additional items added:
The number of CUDA threads that execute the kernel for a given kernel call is specified using a new <<< ... >>> - execution configuration syntax
In the simple example N threads execute the vectAdd() function.
The number of threads per block and the number of blocks per grid specified in the <<< ... >>> syntax can be of type int or dim3
The CUDA Programming Model
The dim3 type is an example of a built-in CUDA vector type.
A dim3 type variable can be created by specifying a value for each dimension:
/* Creates a 16 x 16 x 1 dim3 named threadsPerBlock */
dim3 threadsPerBlock(16, 16);
/* Create a 4 x 4 x 2 dim3 named numBlocks */
dim3 numBlocks(4,4,2);
...
/* These can then be used in the execution config. for a kernel. */
The CUDA Programming Model
Our snippet of code does not include any memory allocation for copy functionality to get the vectors on to the GPU.
Recall that the GPU and the Host have separate memory spaces.
The CUDA kernel is not able to access the static and heap memory allocated on the Host.
We need to explicitly allocate dynamic memory on the GPU and copy the data between the Host and Device.
The CUDA Programming Model
To allocate memory on the we need to use the cudaMalloc( ... ) call:
Frees the memory space pointed to by devPtr, which must have been returned by a call to cudaMalloc().
If cudaFree(devPtr) has already been called before, an error is returned.
cudaFree() returns cudaErrorInvalidDevicePointer in case of failure.
The CUDA Programming Model
The full list of CUDA error types is available in the documentation.
As usual we should be checking the return values for errors!
Some of the examples that I will be working with have the error checking removed to make them clearer.
The CUDA Programming Model
Once we have some memory allocated, we can copy data from the host to the device. Once we have completed our computation on the device we will need to copy the results back to the host.
This is achieved by using the cudaMemcpy( ... ) function: